重复内容对许多人来说,好像披着一层神秘的面纱,总是害怕会因此受到惩罚或是对网站造成某些伤害,却又不确定实际上会带来什么影响、在SEO上该怎么做。这篇文章,将以Google搜索引擎为主,告诉你重复内容的可能影响与应对方针。
- 什么是重复内容?
- 发生重复内容的原因?
- 重复内容会带来什么影响?
- 该如何处理重复内容?
什么是重复内容?
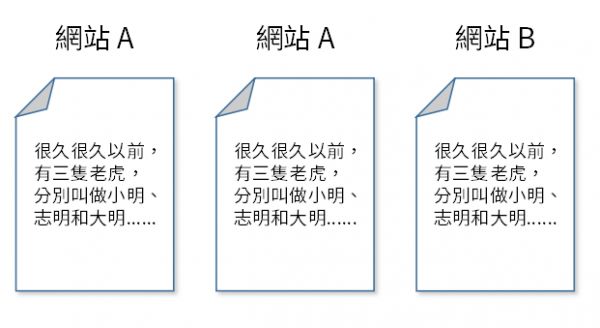
重复内容指的是完全相同或大致相同的内容,重复出现在不同网址(URL)上,此情况可能发生在同网站内或不同网站上。
尽管并不见得会直接导致惩罚,重复内容还是会对搜索排名造成影响。直观的理解,当搜索引擎在网络上的不同处找到相同的内容,就面临了该呈现哪一个与如何呈现的问题。
发生重复内容的原因?
重复内容可能因为以下原因产生:
(1) 支持多种设备的不同网址
https://example.com/products/cups
https://m.example.com/products/cups
https://amp.example.com/products/cups
(2) 因为参数或是SessionID等因素产生的动态网址
https://example.com/products?color=yellow
https://example.com/products?sessionid=5487
https://example.com/products?
(3) www与非www的网址
https://www.example.com/products/cups
https://example.com/products/cups
(4) http、https的不同网址
http://example.com/products/cups
https://example.com/products/cups
(5) 首页的不同网址
https://example.com
https://example.com/index.html
(6) 转载或抄袭
除了文章外,产品信息也会遇到类似的状况,假如有许多网站都贩卖同样的商品,但是都用生产商所提供的文本张贴在各自的网页上,就会造成重复内容出现在不同网站上。
重复内容会带来什么影响?
2008年时,Susan Moskwa在Google Webmaster Central Blog提到:
Let's put this to bed once and for all, folks: There's no such thing as a "duplicate content penalty." At least, not in the way most people mean when they say that.
并没有所谓重复内容的惩罚,至少,并不如大家所想的那样。
这样讲起来还是挺模糊,到底实际上会造成什么影响呢?
先稍微看段影片
Matt Cutts在这部2013年底发布的影片中表示:在网络上,大约有25%-30%的内容是重复的。
实际上发生重复内容的比例并不是那么重要,重点在于:并不是每个重复内容都是在恶意或是不受鼓励的状态下产生,重复内容是可能在正常的情况下发生的,例如:在博客引用其他人的内容。
Google是在上述的前提下处理重复内容的,一般情况下,重复内容不会被视为不当内容,但是Google并不想将相同的内容全部展列出来,所以会考虑许多因素后,从中挑出原创或是可能最实用的版本展示。若用户想要看到未经过筛选的内容再自行透过filter参数更改搜索选项。
但是,当重复内容是为了操纵搜索结果,或者网页目的就是复制内容,并且没有提供更多的附加价值时,就违反了的方针,网站的排名可能因此降低,或者被从索引中移除。
重复内容可以大致分为两个状况讨论:
(1)在同一个网站内发生
在这个情况下,除非是为了欺骗或操纵搜索引擎,若网站主不做任何处理,则搜索引擎会自行从中挑出所要显示的版本,也就是所谓的「标准网页(canonical page)」。
搜索引擎对标准网页的检索频率会比起其他重复的网页来的高,若Google所认定的标准网页与你所认定的不同,且没有想办法让Googlebot知道,则你想经营的页面可能不会创建索引、或是不易出现在搜索结果中。把检索的资源花在重复内容的网页上,也可能排挤到Googlebot对其他网页的检索性能。
另外一个造成的影响是:如果网站上相同的内容分布在多个网页上,则其他网站所创建的链接网址也可能是分散的,比起全部都链接到同一个网址,会分散排名能力与单一网页的曝光程度。
(2)重复内容出现在其他网站上
交给搜索引擎判断不同网站间的重复内容,哪个是原创版本,有可能出现判断失准的状况,让原本是原创的页面被当作转载或是抄袭的,这对于原创者无异是重大的打击。
该如何处理重复内容?
处理重复内容的大方向就是:指出标准版本
以下一些列出可能的做法,在不同情况下应斟酌使用。
(1) 减少相似的内容
听起来或许有点废话,好比不想出错,平常就要细心一点一样,但这一点还是必须要在第一点做提醒。
在产生内容的时候,就应该要考虑到是否会发生重复内容的问题。如果你有相似的页面,可以考虑合并页面上的信息到单一页面中,或是针对差异点各自扩充内容,以更详细的内容区别两个网页。
(2) 避免每页重复出现的内容
假如网站最下方有冗长的公司介绍或是版权说明,并且该区块的内容会套用到每一个页面,建议可以将说明文本修短,放置链接到详细哦明页面。
(3) 使用一致的内部链接
在网站的内部链接,保持一致,不要在不同处分别放置连到重复页面的不同链接。
(4) 联盟发布或投稿的处理
如果你会在其他内容平台上发布你原创的相同内容,Google所选出的版本可能不会是你偏好的那个。确定你发布内容的其他网页都包含连回原始文章的链接。并请该联合发布的网站使用noindex标记,以免索引到非原创版本。
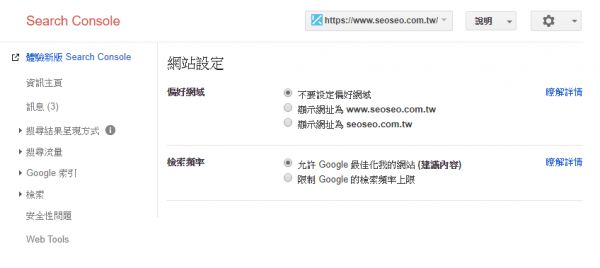
(5) 指定偏好的网域
当两个网站只有子网域不同时,可以透过Search Console将其中一个网域的网址定义为标准网页。例如以下两个网页:
https://example.com
https://www.example.com
你可以将偏好网域设置为上者,作为搜索结果中使用的版本,则Google会将https://www.example.com视为https://example.com的重复项目。
接下来的几点,主要是关于如何定义同一个网站内,重复内容中的「标准网页」
(6) 使用rel="canonical"标记
在所有重复网页的 head 区段中,使用链接元素的rel="canonical"标记来指出该网页与标准网页重复。
范例如下:
在重复网页的 head 区段中添加如下的标签,并将href后方的网址改为你所要指定的标准网页网址

针对带有SessionID的页面也可以用相同的方式处理,如此一来,所有带有SeesionID页面的权重都会集中到所指定的标准页面。
(7) 提交网站地图(sitemap)
你可以为你的不同页面挑选标准网址,并透过网页地图提交。在网站地图中所列出的页面就代表着建议的标准页面,而Googlebot会依相似程度判断是否有其他页面属于重复内容的网页。
只不过,Google并不保证一定会将网站地图中的网址视为标准网址,Sitemap的指针效力不及rel=canonical的作法,但是定义标准网页较为简便的方法,同时也可以告知Google网站上的哪些页面较为重要。
(8) 使用301重新导向
如果有重复网页需要淘汰,可以使用301重新导向将流量导引至偏好的标准网页。
这样做的好处在于,除了告知Google较佳版本的网址,同时也让重复页面的流量集中到标准网页。
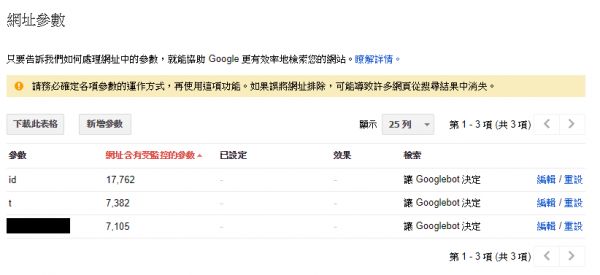
(9) 在Google Console中处理网址参数
在Google Console中,会列出爬虫所遇到的参数,你可以让它自行决定处理的方式,或是自行设置偏好的处理方式。
针对各个参数,你可以决定是否检索带有该参数的网址,可以减少因参数产生的动态网址造成的重复内容问题。
(10) Google不建议用于处理重复内容的方式
- 使用robots.txt禁止对重复网页的检索
- 使用网址移除工具进行标准网页的定义
以上所列的10个方法,都是创建在重复的内容是在原创者合意的情况下。
如果有其他网站在未经授权的情况下,使用你所原创的内容,你可以请对方移除涉及侵权的内容,或是根据提出要求,请Google移除该结果。
cover image credit:
本文网址: https://www.mamioo.com/seo-tuiguang/n4v57rmoa861


留言评论